アーキテクチャ概観¶
この文書では、Scrapyのアーキテクチャとそのコンポーネントの相互作用について説明します。
概観¶
以下の図は、Scrapyアーキテクチャの概要とそのコンポーネント、およびシステム内で発生するデータフローの概要(赤い矢印で表示)を示しています。コンポーネントの簡単な説明と、それらの詳細情報へのリンクを以下に示します。データフローについても以下で説明します。
データ・フロー¶
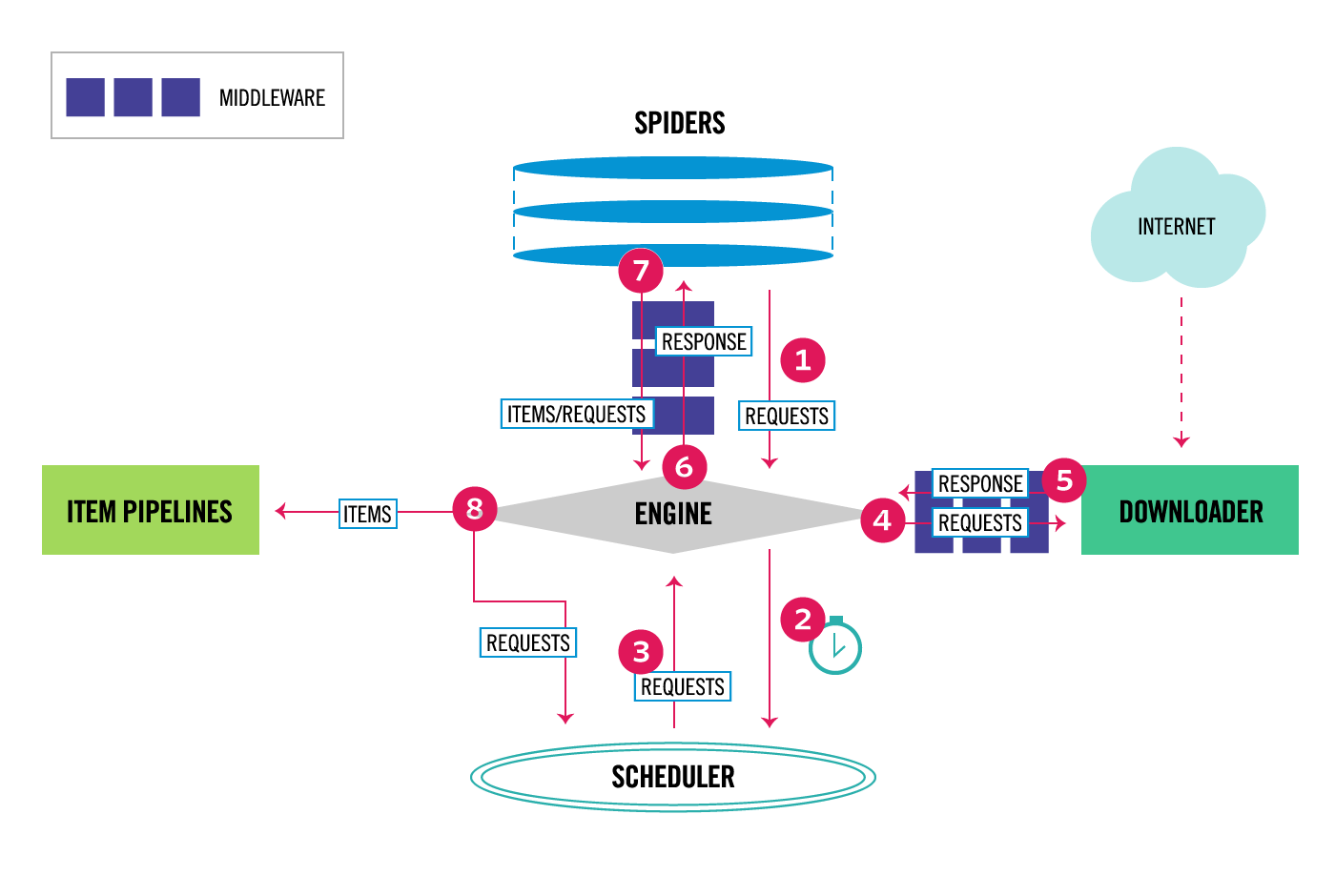
Scrapyのデータ・フローは実行エンジンによって制御され、次のようになります:
Scrapyエンジン は、 スパイダー からクロールする最初のリクエストを取得します。
Scrapyエンジン は、 スケジューラ でリクエストをスケジュールし、クロールする次のリクエストを求めます。
スケジューラ は、次のリクエストを Scrapyエンジン に返します。
Scrapyエンジン は、 ダウンローダー にリクエストを送信し、 ダウンローダー・ミドルウェア を通過します(
process_request()参照)。ページのダウンロードが完了すると、 ダウンローダー は(そのページの)レスポンスを生成し、Scrapyエンジンに送信し、 ダウンローダー・ミドルウェア を通過します(
process_response()参照)。Scrapyエンジン は ダウンローダー からResponseを受け取り、それを スパイダー に送信して処理し、 スパイダー・ミドルウェア を通過します( see
process_spider_input())。スパイダー はレスポンスを処理し、スクレイピングされたアイテムと(後に続く)新しいリクエストを Scrapyエンジン に返し、 スパイダー・ミドルウェア を通過します(
process_spider_output()参照 )。Scrapyエンジン は処理済みのアイテムを アイテム・パイプライン に送信し、処理済みのリクエストを スケジューラ に送信し、可能なら次のクロール要求を求めます。
スケジューラ からの要求がなくなるまで、プロセスは(ステップ1から)繰り返されます。
コンポーネント¶
Scrapyエンジン¶
エンジンは、システムのすべてのコンポーネント間のデータ・フローを制御し、特定のアクションが発生したときにイベントをトリガーします。詳細については、上記の データ・フロー 節を参照してください。
スケジューラ¶
スケジューラはScrapyエンジンからリクエストを受信し、後でScrapyエンジンが求めたときにリクエストをキューに入れて(Scrapyエンジンにも)送信します。
ダウンローダー¶
ダウンローダーはWebページを取得し、それらをScrapyエンジンに送り、Scrapyエンジンがそれらをスパイダーに送ります。
スパイダー¶
スパイダーは、Scrapyユーザーによって作成されたカスタムクラスであり、レスポンスをパースして、レスポンスまたは追跡する追加のレスポンスから アイテム を抽出します。詳細については スパイダー を参照してください。
アイテム・パイプライン¶
アイテム・パイプラインは、スパイダーによってアイテムが抽出(またはスクレイピング)された後にアイテムを処理する役割を果たします。典型的なタスクには、クレンジング、検証、永続化(データベースへのアイテムの保存など)が含まれます。詳細については、 アイテム・パイプライン を参照してください。
ダウンローダー・ミドルウェア¶
ダウンローダー・ミドルウェアは、エンジンとダウンローダーの間にある特定のフックであり、エンジンからダウンローダーに渡されるときにリクエストを処理し、ダウンローダーからエンジンに渡されるリクエストを処理します。
あなたが以下のいずれかを行う必要がある場合は、ダウンローダー・ミドルウェアを使用します:
ダウンローダーに送信される直前にリクエストを処理します(Scrapyがウェブサイトにリクエストを送信する直前);
スパイダーに渡す前に受信したリクエストを変更する;
受信したレスポンスをスパイダーに渡すのではなく、新しいリクエストを送信します;
Webページを取得せずにスパイダーにレスポンスを渡す;
いくつかのリクエストを黙って廃棄する。
詳細は ダウンローダー・ミドルウェア 参照。
スパイダー・ミドルウェア¶
スパイダー・ミドルウェアは、エンジンとスパイダーの間にある特定のフックであり、スパイダーの入力(レスポンス)と出力(アイテムとリクエスト)を処理できます。
あなたが必要な場合はスパイダー・ミドルウェアを使用します
スパイダー・コールバックのポスト・プロセス出力 - リクエストまたはアイテムの変更/追加/削除;
start_requests の後処理;
スパイダー例外を処理します;
レスポンス内容に基づいて、一部のリクエストに対してコールバックの代わりに偉ー・バック(errback)を呼び出します。
詳細については スパイダー・ミドルウェア 参照。
イベント駆動型ネットワーキング¶
Scrapyは、Python用の人気のあるイベント駆動型ネットワーク・フレームワークである Twisted を使って記述されています。したがって、並行性のために非ブロッキング(別名「非同期」)コードを使用して実装されています。
非同期プログラミングとTwistedの詳細については、これらのリンクを参照してください:
Twisted - こんにちは、非同期プログラミング(Twisted - hello, asynchronous programming)
Twisted紹介 - Krondo(Twisted Introduction - Krondo)