Webブラウザの開発ツールを使ってスクレイピングする¶
ここでは、ブラウザの開発ツールを使用してスクレイピング・プロセスを簡単にする方法に関する一般的なガイドを示します。 今日、ほとんどすべてのブラウザには Developer Tools が組み込まれています。このガイドではFirefoxを使用しますが、概念は他のブラウザにも適用できます。
このガイドでは、 quotes.toscrape.com をスクレイピングすることにより、ブラウザーの開発ツールから使用する基本的なツールを紹介します。
ライブ・ブラウザDOMの検査に関する注意事項¶
開発ツールはライブ・ブラウザDOMで動作するため、ページ・ソースの検査時に実際に表示されるのは元のHTMLではなく、ブラウザのクリーンアップを適用してJavascriptコードを実行した後の変更されたHTMLです。特に、Firefoxは <tbody> 要素をテーブルに追加することで知られています。一方、Scrapyは元のページのHTMLを変更しないため、XPath式で <tbody> を使用すると、データを抽出できません。
したがって、あなたは次のことに注意してください:
Scrapyで使用されるXPathを探すDOMの検査中にJavaScriptを無効にします(開発ツールの設定で「JavaScriptを無効化」をクリックします)
フルパスのXPath式を使用せず、(
id、class、widthなどのような)属性またはcontains(@href, 'image')のような識別機能に基づいた相対的で賢いパスを使用してください。あなたが何をしているのか本当に理解していない限り、あなたのXPath式に
<tbody>要素を含めないでください。
ウェブサイトの検査¶
開発ツールの最も便利な機能はインスペクター(Inspector)機能です。これにより、Webページの基になるHTMLコードを検査できます。インスペクターをデモンストレーションするために、 quotes.toscrape.com -siteを見てみましょう。
このサイトには、特定のタグを含むさまざまな著者からの合計10個の引用と、トップ10のタグがあります。 著者、タグなどに関するメタ情報なしで、このページのすべての引用を抽出したいとしましょう。
ページのソースコード全体を表示する代わりに、引用を右クリックして「要素の検査(Q)」を選択するだけで、インスペクターが開きます。その中に次のようなものが見えるはずです:
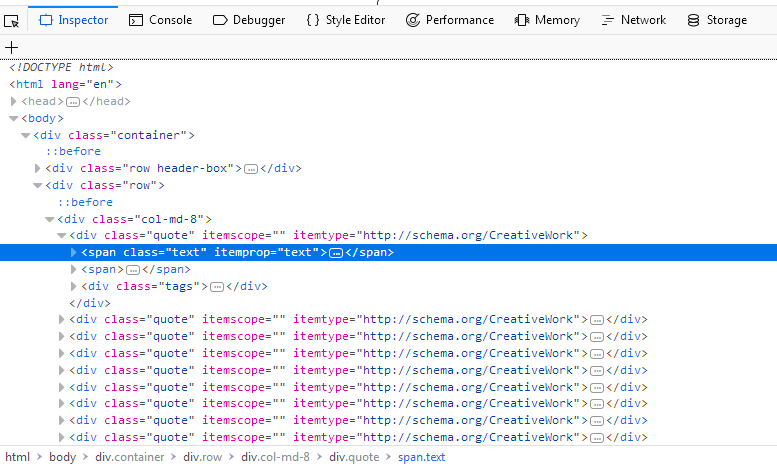
私たちにとって興味深い部分はこれです:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">(...)</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
スクリーンショットで強調表示された span タグのすぐ上の最初の div にカーソルを合わせると、Webページの対応するセクションも強調表示されます。 これで私たちはセクションを得ましたが、引用テキストはどこにも見つかりません。
インスペクタの利点は、Webページのセクションとタグを自動的に展開および折りたたむことであり、読みやすさが大幅に向上します。タグの前にある矢印をクリックするか、タグを直接ダブルクリックして、タグを展開したり折りたたんだりできます。span タグを class= "text" で展開すると、クリックした引用テキストが表示されます。 Inspector を使用すると、XPathを選択した要素にコピーできます。試してみましょう。
まず、ターミナルのScrapyシェルで http://quotes.toscrape.com/ を開きます:
$ scrapy shell "http://quotes.toscrape.com/"
それからWebブラウザに戻り span タグで右クリックし、 Copy > XPath を選んで、以下のようにScrapyシェルに貼り付けします:
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
最後に text() を追加すると、この基本セレクターで最初の引用を抽出できます。しかし、このXPathはあまり賢くありません。それは、ソースコードの html から始まる望ましいパスをたどるだけです。それでは、このXPathを少し改良できるかどうか見てみましょう:
私たちがインスペクターを再びチェックすると、展開された div タグの下に、それぞれが最初の属性と同じ属性を持つ9つの同一の div タグがあることがわかります。それらのいずれかを展開すると、最初の引用と同じ構造が表示されます。2つの span タグと1つの div タグです。 div タグ内の class="text" で各 span タグを展開し、各引用を見ることができます:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
この知識があれば、私たちのXPathを改良できます。たどるパスの代わりに、 has-class-extension を使用して class="text" を持つすべての span タグを選択するだけです:
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
そして、1つの単純で賢いXPathを使用して、ページからすべての引用を抽出できます。 最初のXPathにループを構築して最後の div の数を増やすこともできましたが、これは不必要に複雑であり、単に has-class("text") でXPathを構築することで、すべての引用を1行で抽出できました。
インスペクターには、ソースコードの検索や選択した要素への直接スクロールなど、他の便利な機能がたくさんあります。以下にユースケースを示しましょう:
あなたはページの Next ボタンを見つけたいとします。インスペクターの右上にある検索バーに Next と入力します。2つの結果が得られます。 最初は class="text" を持つ li タグで、2つ目は a タグのテキストです。 a タグを右クリックして、 この要素の位置にスクロール(S) を選択します。ここから リンク抽出器 を簡単に作成して、ページネーションを追跡できます。 このようなシンプルなサイトでは、要素を視覚的に見つける必要はないかもしれませんが、複雑なサイトでは この要素の位置にスクロール(S) 機能は非常に便利です。
検索バーは、CSSセレクターの検索とテストにも使用できることに注意してください。 たとえば、 span.text を検索して、すべての引用テキストを見つけることができます。全文検索の代わりに、これはページ内で class="text" を持つ span タグを正確に検索します。
ネットワーク・ツール¶
スクレイピング中に、ページの一部が複数のリクエストを介して動的にロードされる動的Webページに遭遇する場合があります。これは非常に難しい場合がありますが、開発ツールの「ネットワーク」ツールはこのタスクを非常に容易にします。ネットワーク・ツールをデモンストレーションするために、ページ quotes.toscrape.com/scroll を見てみましょう。
このページは基本的な quotes.toscrape.com -page に非常に似ていますが、上記の Next ボタンの代わりに、ページを下にスクロールすると自動的に新しい引用を読み込みます。先に進んでさまざまなXPathを直接試すこともできますが、代わりにScrapyシェルから別の非常に便利なコマンドをチェックします:
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
ブラウザーウィンドウはWebページで開きますが、1つの重要な違いがあります。引用の代わりに、Loading... という語が付いた緑がかったバーが表示されるだけです。

view(response) コマンドにより、シェルまたは後でスパイダーがサーバーから受信するレスポンスを表示できます。ここでは、タイトル、ログイン・ボタン、フッターを含むいくつかの基本的なテンプレートが読み込まれていますが、引用が欠落しています。これは、引用が quotes.toscrape/scroll とは異なるリクエストからロードされていることを示しています。
「ネットワーク」タブをクリックすると、おそらく2つのエントリしか表示されません。最初に行うことは、「永続ログ」をクリックして永続ログを有効にすることです。このオプションを無効にすると、別のページに移動するたびにログが自動的にクリアされます。ログをクリアするタイミングを制御できるため、このオプションを有効にするのは良い怠慢です。
ここでページをリロードすると、ログに6つの新しいリクエストが表示されます。
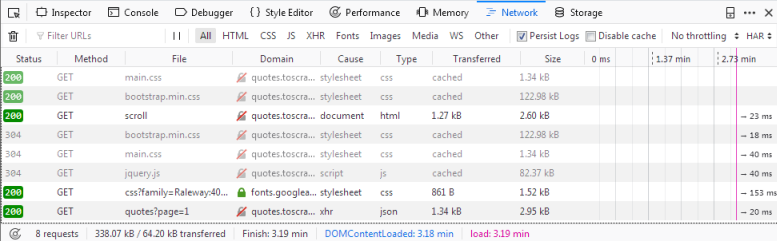
ここでは、ページのリロード時に行われたすべてのリクエストが表示され、各リクエストとそのレスポンスを検査できます。それでは、私たちの引用がどこから来ているのかを見てみましょう:
最初に scroll という名前のリクエストをクリックします。 開発ツール画面の右側で、リクエストを検査できます。ヘッダー・タブには、URL、メソッド、IPアドレスなどのリクエスト・ヘッダーに関する詳細があります。 他のタブは無視し、レスポンス を直接クリックします。
プレビュー・ペインに表示されるのはレンダリングされたHTMLコードです。これは、シェルで view(response) を呼び出したときに見たものです。 したがって、ログ内のリクエストの type は html です。 他のリクエストには css や js などのタイプがありますが、興味深いのは、タイプが json の quotes?page=1 と呼ばれるリクエストです。
このリクエストをクリックすると、リクエストURLが http://quotes.toscrape.com/api/quotes?page=1 であり、レスポンスが引用を含むJSONオブジェクトであることがわかります。 また、リクエストを右クリックして「新しいタブで開く」(Open in new tab)を開いて、概要を確認することもできます。
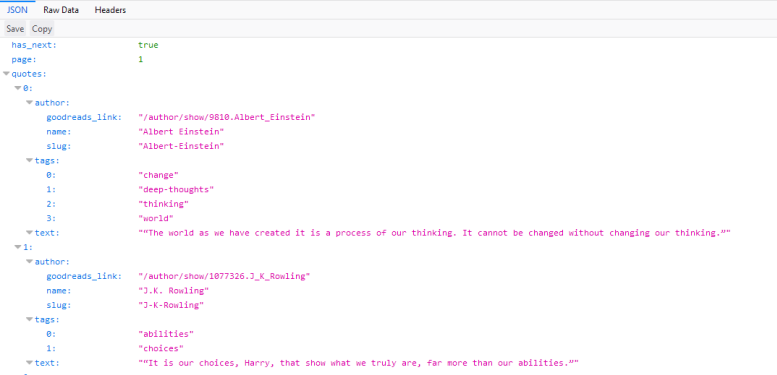
このレスポンスにより、JSONオブジェクトを簡単にパースし、各ページにサイト上のすべての引用を取得するようリクエストすることができます。
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api/quotes?page=1']
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = f"http://quotes.toscrape.com/api/quotes?page={self.page}"
yield scrapy.Request(url=url, callback=self.parse)
このスパイダーはquotes-APIの最初のページから始まります。各レスポンスで、 response.text をパースし、 data に割り当てます。 これにより、Python辞書のようにJSONオブジェクトを操作できます。 quotes を繰り返し処理し、 quote["text"] を出力します。 便利な has_next 要素が true の場合(ブラウザーに quotes.toscrape.com/api/quotes?page=10 または10より大きいページ番号をロードしてみてください)、 page 属性と新しいリクエストを生成( yield )し、インクリメントしたページ番号を url に挿入します。
より複雑なWebサイトでは、リクエストを簡単に再現するのが難しい場合があります。リクエストを機能させるにはヘッダーまたはクッキーを追加する必要があるからです。これらの場合、ネットワーク・ツールで各リクエストを右クリックし、 from_curl() メソッドを使用して同等のリクエストを生成することにより、リクエストを cURL 形式でエクスポートできます。
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
あるいは、そのリクエストを再作成するために必要な引数を知りたい場合、 curl_to_request_kwargs() 関数を使用して同等の引数を持つ辞書を取得できます:
- scrapy.utils.curl.curl_to_request_kwargs(curl_command, ignore_unknown_options=True)[ソース]¶
cURLコマンド構文をリクエストkwargsに変換します。
cURLコマンドをScrapyリクエストに変換するには、 curl2scrapy を使用することもできます。
ご覧のとおり、ネットワーク・ツールでいくつかの検査を行うことで、ページのスクロール機能の動的リクエストを簡単に複製できました。 動的ページのクロールは非常に困難な場合があり、ページは非常に複雑になる可能性がありますが、最終的には正しいリクエストを識別し、それをスパイダーで複製することになります。